- ASC Proceedings of the 42nd Annual Conference
- Colorado State University Fort Collins, Colorado
- April 20 - 22, 2006
|
|
|
Information Foraging and Extraction Techniques for Internet-Based Literature and Data
|
John J. Hannon The University of Southern Mississippi Hattiesburg, Mississippi |
|
As a relative newcomer to academia and formalized research in general, the author has experienced almost three years of student thesis preparation in a Construction Management graduate program. Engagement with these students has revealed a genuine lack of a systematic methodology for identifying internet data sources and exploring and extracting information from this vast depository of information. Aside from motivational factors, many students are unaware of the ever-increasing archives of information accessible through professional associations, research centers, community discussion sites, and blogs. In addition, the students appear ill-equipped to determine the validity and quality of what they discover online. This paper attempts to provide a simple methodology of search and extraction techniques which will assist students in successfully increasing the quantity and validating the quality of information extracted from the internet. The paper is focused solely on the obtainment of information available through Internet-based sources while realizing that currently there are ‘information patches’ of great value not provided through this medium.
Key Words: Infoliteracy, research, Information Foraging, Bibliomining, Information Patches. |
Introduction
“Information Foraging theory…views humans as informavores, continually seeking information from our environment. In a sense we are foraging for information, a process with parallels to how animals forage for food. For both human and animal there are cues in the environment that help us judge whether to continue foraging in the same location or to forage elsewhere.” as written (Withrow, 2002, italics emphasis by author).
The author has been exposed for several years to graduate students commissioned to gather information and knowledge regarding the construction industry in fulfillment of the requirements to complete thesis research for a master’s degree. Many of the students are exposed to the vast dimensions of the construction industry for the first time, having obtained undergraduate degrees in other disciplines. These students often exhibit responses of feeling overwhelmed at the vastness and specialization of the knowledge organizations and their portals. They need direction as to which site destinations, keywords, and disciplines (and sub-disciplines of construction) on which to concentrate their efforts. They also appear challenged in the aspect of managing and documenting the data and sources which they have found.
This paper concerns itself with extraction of literature and data from the Internet in order to perform thesis research. Realizing that this is but a portion of the process called research, the author has shared the student’s frustration with their struggle to find adequate sources of literature. “Research requires the collection and interpretation of data in an attempt to resolve the problem that initiated the research”, (Leedy and Ormond, 2005). Granted, some of the students fail to attain information because they are lazy. The author feels strongly that the majority simply need some direction in method and technique.
As a result of research performed by Peter Pirolli and Stuart Card at Xerox’s Palo Alto Research Center in the 1990s, this mining and extraction process will be henceforth referred to as ‘Information Foraging’.
Methodology
Decomposition of Research Topic
The graduate program at the author’s institution requires the students to define their thesis (research) problem after the first semester of coursework. The degree program takes between one and two years to complete (coursework and thesis). Additionally, the majorities of these graduate students do not have an academic construction background, so the first semester is their initial contact with the vastness of the construction industry’s body of knowledge and required skills. As a result, the thesis problem statements which they initially define are in actuality ‘thesis topics’ which are very broad in nature and scope. This is due in part to their lack of knowledge as to how the industry is configured and segmented by types of construction, public vs. private sectors, delivery methods, occupational functional roles, etc. The students’ trend is to experience difficulty in narrowing their research topic into a manageable problem statement. Some discard the topic completely by the end of the second semester and define a new problem. This appears to be a natural result of their increasing understanding of the industry’s professional scope and structure through coursework which they have taken by that time.
Having learned from more experienced academics, the author proposes a decomposition of the research topic(s) into the various related disciplines of established knowledge and subjects. Once this decomposition has been performed successfully, the student researcher possesses the ‘building blocks’ or foundation of his/her literature and data information forage. The knowledge and subject areas defined from the topic decomposition are utilized when internet searching in the successive steps of the procedure.
An example of this decomposition can be expressed as follows: Assume that a student were interested in the topic of Disadvantaged Business Enterprise (DBE) construction firms (topical area). The decomposition of this subject-topic into disciplines for information foraging purposes might include:
Construction.
Contracts.
Law.
Business organization.
Additionally, applying classifications to the topic from a master list such as the Library of Congress Classification System can be useful. The classification outline can be accessed at the following web address or Uniform Resource Locator (URL):
http://www.loc.gov/catdir/cpso/lcco/lcco.html . The outline consists of a classification hierarchy (with sub classifications) which is useful for decomposing topics into disciplines.
Once the disciplines have been defined, they can be broken down further into subjects. Extension of the previously described example might yield the following:
Construction Discipline: Bidding, contracts, contract administration.
Contracts Discipline: construction, bidding, regulations.
Law Discipline: Federal, statute, regulations, corporate.
Business Organization Discipline: Law, regulations.
Now the subject areas can be decomposed further into detailed topics as displayed in Table 1.
|
Table 1
Broad topic decomposition |
|||
|
Broad Topic |
Discipline |
Subject |
Detailed Topic |
|
DBE Contractors |
1. Construction |
Bidding |
Minority Goals |
|
|
|
Contracts |
|
|
|
|
Contract Administration |
|
|
|
2. Contracts |
Construction |
Prequalification Certification |
|
|
|
Bidding |
|
|
|
|
Regulations |
|
|
|
3. Law |
Federal |
Qualification Set-Asides 8-A |
|
|
|
Statute |
|
|
|
|
Regulations |
|
|
|
|
Corporate |
|
|
|
4. Business Organization |
Law |
Organization Types Business Ownership |
|
|
|
Regulations |
|
|
|
|
|
|
This initial decomposition process could first be attempted by the students after they learn the basic methodology. In the author’s specific case, the students lack sufficient knowledge of the construction industry at this point in their candidacy. Therefore, the students’ advisor or graduate committee chair would assist in this process after their first iteration.
Synthesize Collections of Keywords
Since Internet search engines operate by matching strings of text entered by the user to text strings in files and web pages, the production of a master keyword collection is the next step in the information foraging procedure. The keywords (and combinations) will be input to the search engine to produce document and web page matches for view and extraction by the forager. There is an entire scientific discipline known as synonymy, which studies the semantics of words and maps synonyms with various vocabularies. Once students produce an initial list of keywords, they should utilize online sources such as http://thesaurus.reference.com to develop a list of synonyms to add to their keyword list.
Continuing with the example, the topic decomposition provides the basis of initial search engine terms. Concatenation of the words in Table 1 produces keyword search text strings. Any combinations of the words are valid, but performing the exercise in a spreadsheet results in the following strings. The plus sign separator designates the Boolean logical operator, ‘AND’, which instructs the search engine to return data containing all of the phrases in the string. The search terms which can now be inserted into the search engine are as follows in Table 2:
|
Table 2
Broad topic decomposition resultant text strings with Boolean logical operator |
|
Search Engine Text Strings |
|
DBE Contractors+Construction+Bidding+Minority Goals |
|
DBE Contractors+Construction+Contracts+Minority Goals |
|
DBE Contractors+Construction+Contract Administration+Minority Goals |
|
DBE Contractors+Contracts+Construction+Prequalification |
|
DBE Contractors+Contracts+Bidding+Certification |
|
DBE Contractors+Contracts+Regulations+Certification |
|
DBE Contractors+Law+Federal+Qualification |
|
DBE Contractors+Law+Statute+Set-Asides |
|
DBE Contractors+Law+Regulations+8-A |
|
DBE Contractors+Law+Corporate |
|
DBE Contractors+Business Organization+Law+Organization Types |
|
DBE Contractors+Business Organization+Regulations+Business Ownership |
|
|
Obtain Search and Extraction Tools
“There is no such thing as information overload. All you have to do is narrow your search, or
re-evaluate what you thought you were looking for. Because the tools are more powerful, they require more thought to use effectively” as written (misanthrope101/Slashdot poster 2005).
Finding and extracting information from the internet involves the use of software applications. By utilizing readily available software tools, this step in the process can be both efficient and effective. The use of these applications can compress the search time required many times over compared to conventional web page browsing. Details regarding these tools and their usage will be offered in the later portion of the paper.
Understand Search Engine Basics
One of the most impressive sources the author discovered while researching for this topic was that of Marcus P. Zillman. Mr. Zillman is a consultant and speaker who has authored numerous whitepapers, books, and seminars on information retrieval, knowledge discovery, knowledge harvesting, artificial intelligence, and intelligent agents. His short definition describing how search engines operate is worthy of quoting, “ Search engines on the Internet are powered by ‘bots’ that actively go out and search for meta description and keywords in files that are placed on the Internet. When you visit the search engine and type in the keyword or phrase that you are looking for, the results that are generated come from the latest searching by the search engine’s bots that are deposited in the search engine’s database” as written (Zillman, 2005).
Also, “Search engines run automated programs, called "bots" or "spiders" that use the hyperlink structure of the web to "crawl" the pages and documents that make up the World Wide Web. Estimates are that of the approximately 20 billion existing pages, search engines have crawled between 8 and 10 billion. Once a page has been crawled, it's contents can be "indexed" - stored in a giant database of documents that makes up a search engine's "index". This index needs to be tightly managed, so that requests which must search and sort billions of documents can be completed in fractions of a second. When a request for information comes into the search engine (hundreds of millions do each day), the engine retrieves from its index of all the documents that match the query. A match is determined if the terms or phrase is found on the page in the manner specified by the user. For example, a search for ‘car and driver magazine’ at Google returns 8.25 million results, but a search for the same phrase in quotes ("car and driver magazine") returns only 166 thousand results. In the first system, commonly called "Findall" mode, Google returned all documents which had the terms "car" "driver" and "magazine" (they ignore the term "and" because it's not useful to narrowing the results), while in the second search, only those pages with the exact phrase "car and driver magazine" were returned. Other advanced operators (Google has a list of 11 at http://www.google.com/help/operators.html) can change which results a search engine will consider a match for a given query. Once the search engine has determined which results are a match for the query, the engine's algorithm (a mathematical equation commonly used for sorting) runs calculations on each of the results to determine which is most relevant to the given query. They sort these on the results pages in order from most relevant to least so that users can make a choice about which to select.” as written (Fishkin, 2005)
Students should explore the Boolean operators available on the search engine website and experiment with different search term text strings and results. This makes an excellent assignment exercise in a thesis or research course. University Libraries at the University of Albany currently posts a webpage ‘Boolean searching on the Internet: A Primer in Boolean Logic’ at http://library.albany.edu/internet/boolean.html as well as tutorials regarding the use and search of the Web.
Define Information Sources
Once the keyword combinations have been adequately defined by the student, information sources can be located through their use in the search engines. Experimentation with different combinations of keywords and synonyms can yield eclectic results. With assistance and validation from graduate committee members, instructors, and/or other topical experts, a solid foundation of web-based sources can be identified. This portion of the information foraging process also lends itself well to an exercise or assignment to be presented to the graduate committee. Although this will be an ongoing process throughout the entire information forage related to the research project (thesis), the first iteration will define initial targets for information extraction. The definitions should be targeted to the following sources of information:
Professional Association Websites
Professional Associations typically provide access to specialized magazines, articles, papers, and other technical documents authored by experts and peer-reviewed by other members of the association. In the example previously described, the keyword combinations yielded the following professional association sources: American Subcontractors Association (ASA), Minority Professional Network, and Oregon Association of Minority Entrepreneurs (OAME).
Governmental Organizations
Governmental organizations are typically excellent sources of information and data. Federal government websites contain significant amounts of good quality data for mining. This is especially applicable in our example case because it strongly infers public-sector construction. Federal, State Departments of Transportation (DOTs), and other transit agencies are worthy of exploration. As an advisor to the student, the author would recommend exploration of the following governmental organizations: Equal Employment Opportunity Commission (EEOC), Federal Highway Administration (FHWA), State DOTs, Federal Acquisition Regulation (FAR), and American Association of State Highway and Transportation Officials (AASHTO). Usage of the example keyword strings located the Office of Small and Disadvantaged Business Utilization and Minority Resource Center (OSDBU/MRC) website. The OSDBU organization is a part of the U.S. Department of Transportation.
Academic Proceedings and Journals
Academic literature sites are typically categorized by discipline and should be deeply explored as part of the information foraging process. Data and literature mined from academic sources has the validated insurance of the peer review process. There are several of these types of organizations which are professionally oriented with the collaboration of academia (related to the construction industry). Some in the United States include: Journal of Construction Education (ASC), Journal of the American Institute of Constructors (AIC), Associated Schools of Construction Annual Conference Proceedings (ASC), Association for the Advancement of Cost Engineering International (AACE International), and FIATECH. Colorado State University currently posts a webpage containing a listing of such sites at http://www.cahs.colostate.edu/cm/CMARC_journals.stm .
Searches utilizing the previous example’s keyword search strings located The National Association of Multicultural Engineering Program Advocates (NAMEPA).
News Media
The Internet acts as an incredible aggregator of daily news across the world. As construction is an integral part of society and employs a significant portion of the world’s human and financial resources, the chances of obtaining pertinent material for construction-related research on a daily basis are high. Newspapers and magazines in paper print are losing readership to online viewers at an increasing rate. There are currently available numerous new sites which aggregate worldwide information daily. There are also a significant number of construction news magazines which students should discover and bookmark in their browsers. Two examples of these types of web sites are Engineering News Record (ENR) and LexisNexis News.
Blogs
“A blog is a website in which journal entries are posted on a regular basis and displayed in reverse chronological order. The term blog is a shortened form of weblog or web log. Authoring a blog, maintaining a blog or adding an article to an existing blog is called "blogging". Individual articles on a blog are called "blog posts," "posts" or "entries". A person who posts these entries is called a "blogger". A blog comprises hypertext, images, and links (to other webpages and to video, audio, and other files). Blogs use a conversational style of documentation. Often blogs focus on a particular area of interest. Some blogs discuss personal experiences.” as written, (Wikipedia, 2006). Depending on the author’s status and motivation for blogging, there can be huge ranges in the literature and data quality of blogs. Two examples of blogs beneficial to research are from professor Lawrence Lessig of Stanford, considered the foremost expert in intellectual property law related to the Internet (http://www.lessig.org/blog/) , and Marcus P. Zillman who is quoted and referenced elsewhere in this paper (http://zillman.blogspot.com/).
Online Databases
Databases on the Internet are numerous, beneficial, and relatively easy to find. The students should start with their institution’s library web page. At the author’s university, the library offers an incredible selection of databases for information foraging. All students should explore these options. In addition, there are a growing number of citation sites such as Google Scholar which broadly search for peer-reviewed papers, theses, books, abstracts, and articles from academic publishers, professional societies, universities and other scholarly organizations. Continuing with the previous example, the university website at the author’s institution provides the LexisNexis legal research database which provides significant search results from a minimal number of keywords related to ‘DBE’.
References and Bibliographies of Existing Manuscripts
As students locate and extract literature from the Internet, many of the manuscripts obtained will contain abstracts with keywords, reference sections, and bibliographies. As discussed in the next step, these are excellent sources of keywords to utilize in information foraging as well as non-digital links to other sources of information (including valid and critical non-digital sources).
Extract/Collect Data (Data Warehouse)
The purpose of information foraging in our case is to collect literature and data to support thesis research. The next five steps in the process are from the concept of ‘bibliomining’ (data mining in libraries), part of an overall process called Knowledge Discovery in Databases (Nicholson, 2002). The author encourages students to collect literature (legally, respecting U.S. Copyright law) via extraction from the Internet and bookmarking pages which contain literature and data. Extraction is preferred over bookmarking as web site content is variable in nature. By utilization of software application tools discussed later, extraction and collection of Internet search engine results can accomplish the creation of a ‘data warehouse’. The data warehouse is the body of literature and data (files) which will contain the content constituting the Literature Review portion of the research project. It is worth noting that students should be prepared for the financial cost involved in obtaining literature and for storage media. Many web sources charge for articles, books, and papers. Quality portable hard disk and flash media drives are available (at the time of this writing) for the price of a textbook. Students should plan to have at least 20 gigabytes or more of storage available for data warehousing (about the storage space on an average ipod). This step in the information foraging process is an ongoing process which lasts until the student finishes the literature review portion of the thesis.
Validate Data and Sources (Refine Data)
Virtually anyone can contribute content to the network with minimal resources. Information foragers should have some basic instincts regarding the soundness of the literature and data which has now been extracted into the data warehouse. Blogs and commercial marketing whitepapers, although perfectly valid mediums for knowledge and information, should be read with suspicion (everything read should be critically challenged). Students should be aware of the peer-review process performed by most industrial associations and academic journals. When literature is peer reviewed it has been critically accepted by experts in the associated field or discipline. Even peer reviewed literature can contain errors and omissions, but manuscripts produced by this procedure should carry much more validity than non-peer reviewed works.
The Teaching Library at the University of California Berkeley has excellent content regarding the judgment of Web-extracted literature and data.
Comprehend Data (Explore Data)
Thesis students should read, study, and comprehend the literature and data in the warehouse. Credit hours may or may not be awarded for this step in the process, but it must not be minimized. Without a thorough comprehension of the topic and problem, the research project cannot be completed successfully. The researcher should fully understand all of the applicable subject-knowledge areas which were decomposed from the broad research topic in the initial steps of the process.
Refine Data (Utilize, Store, or Discard)
As the students progress past their first semester, they begin to refine their research topic into a research problem. By narrowing the parameters of their research topic into a problem which has solvability within a few semesters, the applicability of the data and literature in the warehouse should be relatively easy to determine. Either the information which has been collected supports the thesis problem or it does not. Extracted data and literature which support the problem statement should be separated from the content which does not. If this procedural step is cumbersome for the student, it is very likely that the problem statement is still too broad and/or the student has not comprehended the data and literature. The author recommends discarding only non-validated information from the data warehouse(s).
Evaluate, Report, and Implement
The validated information in the student’s data warehouse is now used to construct portions of the references or bibliography of the thesis. This collection of literature constitutes the body of existing knowledge which is utilized to support the research project’s problem statement and constitutes the Review of Literature.
Software Application Tools and Features
Web Browser
The basic tool for internet information foraging is the web browser. Currently, the most versatile web browser is a free-cost, open source application called Mozilla Firefox. The browser is available for download at http://www.mozilla.com/firefox . The browser’s history is traceable to the first browser application on the market, Netscape Navigator (Hannon, 2004). Microsoft has announced intentions of emulating Firefox’s features in their next version of Internet Explorer, but currently these features are not available in their application. The advantages of utilizing the Mozilla Firefox web browser include the following features:
Tabbed Browsing.
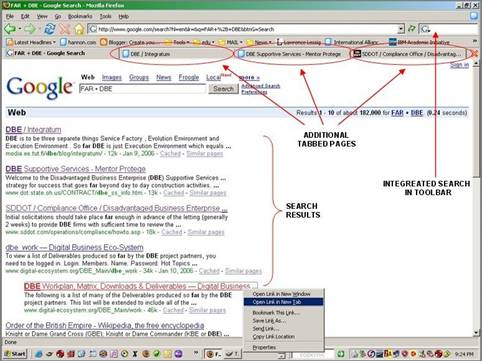
The ability to open and view multiple web pages within the single browser window is called ‘tabbed browsing’. The web pages appear as tabs within the window (similar to tabbed worksheets in a spreadsheet workbook) and allow the user to quickly view and access multiple pages. This is especially useful when utilizing a web-based search engine such as Google. The initial browser tab contains the listing of the search results and can remain open while other tabs display user selected pages from the search. Additionally, all open tabs in the browser window can be bookmarked simultaneously. Corollary features include the ability to open multiple tabbed pages instantaneously from the user’s recorded bookmarks (designated as homepages) and the ability to drag and drop tabs to various positions within the browser window (including bookmarks). Figure 1 displays a Mozilla Firefox browser window with multiple tabs displayed.
|
|
|
Figure 1: Firefox Browser Tabs with Integrated Search Field |
Integrated Search.
The Mozilla Firefox browser contains an entry-field in its toolbar which allows quick access for online searches by keyword or phrase. The browser installs with several search engines pre-loaded and is configurable so that additional search engines can be added to display in the field’s drop-down menu. This feature also allows the user to highlight text on a web page and to drag (with the mouse) the text into the entry-field for instantaneous search utilizing the dragged text as keywords. Figure 1 designates and displays the location of this integrated search entry-field.
Synchronized Bookmarks.
Most of us are familiar with and utilize bookmarks within our browser sessions. In Microsoft’s Internet Explorer browser (IE) they are called ‘Favorites’ (which can be organized into folders called ‘Links’). Mozilla Firefox simply uses the terms ‘bookmarks’ and ‘folders’. Bookmarks are simply stored records of webpage locations (internet addresses) which allow for quick access to web pages which the user anticipates visiting again. Storing bookmarks in your browser alleviates the user from having to memorize them or record them in some other location and from having to type the page address into the browser’s address field. When organized correctly, hundreds of web page locations can be accessed very quickly without the need for search engines.
Because the Mozilla Firefox browser is open source software, users are free to add features to the source code of the application (new features) and the Mozilla organization releases the new code in beta versions for testing and quality assurance. This means that if a user desires a specific feature in the application, the user can contribute the source code for inclusion in the application or as an add-on which Firefox terms as ‘extensions’ or ‘add-ons’. One feature with such a history is called ‘synchronized bookmarks’. This feature allows the user to store collections of bookmarks at remote internet locations as Extensible Markup Language (XML) files and download them to any Mozilla Firefox browser on any computer. It works the opposite way as well; if the user wants to append his/her collection of bookmarks (from any session on any machine) they simply upload them to the remote location. The synchronized bookmark feature is useful for information foragers which utilize more than one computer on a consistent basis. An example would be students which not only forage on their personal computer at home, but also in the lab at the university and on their laptop computer which they take with them to school and work. If any of the computers fail, access to the bookmarks is easily remedied.
The author encourages students to develop and organize effective collections of bookmarks for use throughout their graduate school experience. The synchronized bookmark feature of Mozilla Firefox requires personal web space on the internet. Most people with a personal web page have access to such space. For those who do not, an alternative method of building, storing, and sharing the bookmark collections is to simply export them from the Firefox browser onto media of choice. This Hypertext Markup Language (HTML) file can be imported into Firefox and other browsers for access to the collections.
Social Bookmarks.
As the Internet is currently the ultimate network connecting information foragers (and students), the compulsion to share is inevitable. Students working on research in team assignments would definitely want to take advantage of the sharing of bookmarks or ‘social bookmarks’. Collaboration in bookmark collecting can occur in several ways. As discussed previously, the synchronization feature is available with Firefox, while the export and import of bookmarks is a feature of most browsers.
There exists an online bookmarking service called ‘del.icio.us’ (also the web address) which enables groups to share bookmarks and searches online. This service will also allow information foragers to access their bookmark collections from any machine or browser with an Internet connection (eliminating the requirement for personal web space). The address collections are not accessed from the browser but from the network. Users of del.icio.us must create an account (free of charge) to enable this feature. The site also allows the bookmarks to be organized by keywords called ‘tags’. The idea is that tag organization is of greater benefit than categorical organization when collaboration is emphasized. Regardless, the use of tags is optional on del.icio.us. The Mozilla Firefox browser can utilize del.icio.us via the integrated search field, but any browser can access the service.
Live Bookmarks.
Mozilla Firefox contains a ‘live bookmarks’ feature which in essence functions as an indicator to users that bookmarked web pages have content changes. This is based upon an XML file format called RSS (Really Simple Syndication). Users subscribe to this RSS service if provided by the website and new information is ‘pushed’ to the subscriber’s browser. This is especially useful for news sites and blogs (a website of personal journal entries) which change content daily or periodically.
Applications
There are several other software applications which the author recommends for information foraging as a result of his own experiences. While the web browser is a critical tool, several other software applications have proved very useful. The rate of technological advancement will most likely provide foraging tools which will lessen the importance of these described. The emphasis should be on the functionality of the applications, the manner in which they automate effective and efficient information foraging or knowledge discovery. The author is also confident that this is by no means a comprehensive description of all the available tools for these endeavors.
Copernic Software.
Copernic is a company that produces and markets software for information foragers and managers. Their applications provide tools for indexing, searching, summarizing, and tracking information and data. The company provides software applications for each technological function separately although they can be purchased (at a discount) in a bundle. Two of their offerings are currently available free of cost (with limited functionality) and two of the applications can be utilized on a timed trial basis. Fortunately, the two products most applicable to information foraging are the free ones (although the author recommends licensing the full-featured versions). The author’s descriptions will address the fully featured versions.
Copernic Agent Professional is an application which functions as a bookmarker for web searches. The search results can be filed and stored in folders, exported to most any standard file format, filtered, sorted, and tracked for changes. The application utilizes 16 (currently) search engines on each individual query. Search results are ranked by relevance to the search string, duplicate hits across the search engines are automatically eliminated, and individual search results can be tagged and annotated. In essence, this tool comprehensively increases the productivity, automation and documentation of information foraging compared to individual searches performed in a web browser.
Copernic’s other offerings include ‘Desktop Search’ which indexes the user’s local hard drive. This application allows keyword searches of standard file formats plus Microsoft Office files and Adobe Acrobat files and is incredibly useful for locating extracted files in the user’s data warehouse. This application is a cost-free download. The remaining applications, ‘Summarizer’ and ‘Tracker’ are available on a trial basis and worthy of exploration. All of Copernic’s applications integrate directly with Internet Explorer.
Google Software.
The search engine company, Google, provides software application tools competitive with Copernic. Google’s software applications are cost-free to individual users, while enterprise (business) applications are licensed for fee. Google Desktop is an indexing and search engine for local files while Google Earth (still in beta testing), a Geographical Information System (GIS) search engine browser is becoming popular.
Adobe Acrobat Professional.
Adobe Acrobat is an application which creates documents in the .pdf file format. These documents have become a de facto proprietary standard for exchanging documents created in differing file formats. The application to create the files, Adobe Acrobat Professional, requires a license fee, while the application required to read the files, Adobe Acrobat Reader, is freely distributed. The significant aspect of the Professional application is its ability to capture web pages to local storage. The software integrates with most any application, in this case the web browser, and by invoking the ‘print’ command, the entire web page is captured in .pdf format with the page’s address and the date automatically documented in the file. Student licensing of Adobe Acrobat Professional is available for approximately $175.00.
Conclusion
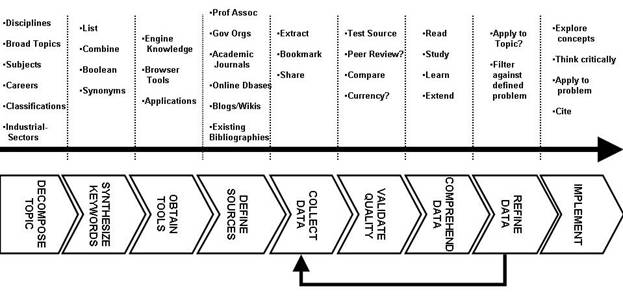
This paper has presented the process steps or methodology involved in literature and data extraction from sources on the Internet. Information technology tools to accomplish the process have been identified and briefly described. If students would study and comprehend this procedure in the course of planning their thesis research projects, time could be saved and frustration could be avoided. Figure 2 visually displays the process steps involved in information foraging.
|
|
|
Figure 2: The Information Foraging Process |
It is hoped that by outlining and describing the process steps involved in information foraging for literature and data associated with a research project, students will be less intimidated by the thesis work which lies before them. There are no doubt additional tips, tricks, tools, and techniques which have not been identified or discussed. Innovations in technology will surely provide enhanced tools for use in this process in the very near future, dating this manuscript quite quickly. Although technology may speed the process and make it more efficient, the process steps of information foraging will likely remain unchanged for some time to come. Research on this topic of information foraging has coined another word and concept, ‘Information Patches’. Information patching refers to how information foragers gather information in pieces from differing sources. A wide range of ‘patches’ is recommended for students engaged in research projects. Some of those sources have been discussed in this paper, but there are a considerable number of sources (books, interviews, etc.) which are not digital (and will never be) and must be considered for the entire scope of the student’s information forage.
References
Fishkin, R. (2005). Beginner's Guide to SEO [Electronic Version]. Retrieved 12/08/05 from http://www.seomoz.org/beginners.php.
Hannon, J. J. (2004). Open Source Software Defined with Considerations for Use in the Construction Contractor's Office. Paper presented at the 2004 Proceedings, Provo, UT.
Leedy, P. D., & Ormrod, J. E. (2005). Practical Research: Planning and Design (8th ed.): Prentice Hall.
Nicholson, S. (2002). The Bibliomining Process. Retrieved 01/10/2006, from http://www.bibliomining.com/bibproc.html
Wikipedia. (2006). The Free Encyclopedia. Retrieved 01/10/2006, from http://en.wikipedia.org/wiki/Blog
Withrow, J. (2002). Do Your Links Stink? Techniques for Good Web Information Scent [Electronic Version]. Bulletin of the American Society for Information Science and Technology, 28. Retrieved 01/06/2006 from http://www.asis.org/Bulletin/Jun-02/withrow.html.
Zillman, M. P. (2005). Searching the Internet [Electronic Version]. Virtual Private Library. Retrieved 12/25/05 from http://zillman.blogspot.com/2004/09/searching-internet-white-paper.html